Inside Git: How It Works and the Role of the .git Folder
Git is a tool that helps you keep track of changes in your code, work with others, and remember what happened in your project over time.
In simple terms, Git records every change you make so you can revisit, revert, or branch off from any point in your project’s life. This makes working with code safer and more organized. and if you wanted to understand more git i have a Git for Beginners: Basics and Essential Commands.
How Git Works Internally: The "Database" You Didn't Know You Were Using
Most people learn Git by memorizing commands. It works, but it never really feels safe. One wrong step and everything looks broken.
Git becomes much easier once you understand what it is actually doing. Git is not magic. It is not a set of rules you have to remember. Git is a storage system that remembers your project over time.
Once you see that, Git starts to make sense.
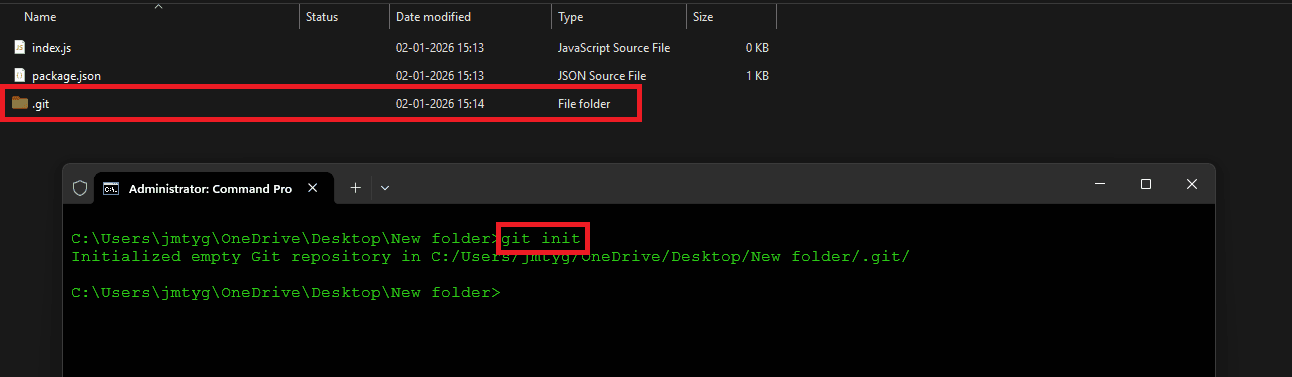
Understanding the .git Folder
When you run git init, Git creates a hidden folder called .git. This folder is the heart of Git. Your project files are just normal files. The real repository lives inside .git.

If you delete the .git folder, Git is gone. Your code stays, but there is no history anymore.
Git uses this folder to store the full history of your project, the saved versions of files, and information about branches and commits. Everything Git knows is written somewhere inside .git

Inside this folder, the most important place is objects.
objects/
— the only place that actually stores data, (This is the database) and Git stores four object types, all compressed and named by hash:
blob – file contents
tree – directory structure
commit – snapshot + metadata
tag – named reference with metadata
Example: Objects are stored by SHA hash:
objects/ab/cdef1234...
The hash is computed from:
type + size + content
refs/
— named pointers, This folder contains names that point to commit hashes.
refs/
heads/
main
feature-x
tags/
v1.0
Each file contains exactly one line:
<commit-hash>
HEAD
— the current pointer, it tells Git which ref is active.
Most of the time it contains:
ref: refs/heads/main
Meaning:
HEAD points to a branch
branch points to a commit
commit points to a tree
tree points to blobs
Detached HEAD is when this file contains a commit hash instead.
index
— the staging area, This file is a temporary snapshot builder.
It maps:
path → blob hash → file mode
Workflow:
git addupdates the indexgit commitreads the indexa tree is built from the index
a commit is created
No index, no staging.
Direct commits would still be possible, but Git’s power comes from this layer.
logs/
— history of pointer movement, This is Git’s safety net.
It records:
where HEAD was
where branches moved
That’s why you can recover “lost” commits.
hooks/
— event scripts, Shell scripts triggered by events:
pre-commit
post-commit
pre-push
They don’t affect Git’s core logic.
info/
— local metadata, Contains things like:
exclude file (local .gitignore)
No objects, no refs
config
— repository settings, This tells Git how to behave, not what exists.
remotes
branches
user overrides
description
— legacy, mostly unused
Used by old Git hosting tools.
COMMIT_EDITMSG
— temporary state and Only exists to support user workflows.
Putting it all together
objects/
Store blobs, trees, commits by hashrefs/
Store names pointing to commit hashesHEAD
Store the current ref or commitindex
Map paths to blob hashes
The main idea is simple. Git is a storage system inside .git. Almost everything else is just a pointer.
Moreover you can read more details about each folder on Git for Beginners.
Diagram idea: Structure of the .git directory

Git Objects: Blob, Tree, Commit
Git saves everything using three basic building blocks. Every Git project uses the same ones.
A blob stores the content of a file.
It does not know the file name or where the file lives.
It only knows what the file contains.
If two files have the same content, Git stores it once and reuses it.
A tree represents a folder. It connects file names to blobs and folder names to other trees. Trees are what give structure to your project.
A commit is a saved snapshot of your project. It points to one main tree, keeps a link to the commit before it, and stores who made the change and why. A commit does not store changes. It stores how the whole project looked at that moment.
The big idea is that blobs store content, trees store structure, and commits store history. Git history is just commits pointing to trees, and trees pointing to blobs.
Diagram idea: Relationship between commits, trees, and blobs

How Git Tracks Changes
Git does not watch files line by line. Instead, it saves full snapshots.
When a file does not change, Git does nothing new. It just points to the same stored content again. This is why Git stays fast even when a project has a long history.
What Happens During git add
When you run git add, Git does not save anything to history yet. It reads the file, saves its content, and remembers that version for later.
This saved version goes into the staging area. The staging area is just a holding place for the next commit.
A simple way to think about git add is this. You are telling Git, “Remember this version of the file.”
What Happens During git commit
When you run git commit, Git takes what is in the staging area and turns it into a snapshot. It builds the folder structure, creates a commit, and moves the branch to point to it.
Only what is staged becomes part of the commit. Your working files are not saved directly.

Diagram idea: Internal flow of git add and git commit

How Git Uses Hashes to Keep Things Safe
Every piece of data in Git gets a unique hash. This hash comes from the content itself.
If the content changes, the hash changes too.
This means Git can always tell if something was changed. Commits are linked together using these hashes. If someone tries to change the past, every commit after it breaks.
This is how Git protects your history.
A Simple Way to Think About Git
If Git feels confusing, keep this picture in your head.
Git is a storage system for snapshots.
Commits point to saved versions of your project. Branches are just names that move forward. git add prepares files, and git commit saves them.
Once you see Git this way, Git stops feeling scary.
You are not fighting Git. You are using a system that is built to remember things carefully.




